We built attractor-basin memory before the paper named the problem
Editor’s note. The architecture below was built across summer 2025 as ContextNest’s memory substrate, at a time when “LLM context management” mostly meant glue between vector DBs and message-history primitives — no reliable organization layer, no consolidation pass, no notion of memory shape beyond cosine similarity. The 2026 framing that lets this post anchor cleanly was added on the 2026-05-12 revision, after arXiv:2604.27003 landed in April 2026 and named the failure mode the 2025 substrate had been trying to head off. The code is the original 2025 build; the literature anchors are the retrospective.
In mid-2025, context management for LLM agents had no reliable organization substrate beneath the vector DBs and message-history primitives: no way to mark a consolidated observation vs. a one-off, no way to encode that high-cosine observations might belong to different basins of meaning, no way to name an observation’s organization at all. Pinecone, Weaviate, Chroma, OpenAI’s messages[] array, LangChain’s ConversationBufferWindowMemory — stitched together, they let you bolt a retrieval call onto an inference call and call the result a memory layer.
We bet the missing layer was a consolidation substrate — a topology of attractor basins with shape, depth, multi-resolution structure, and a health metric that decayed unused regions while reinforcing used ones, not another retrieval index. ContextNest was built around that bet. The first commit landed July 20, 2025; the attractor-based persistence system landed the same week. The literature did not yet have a name for the problem we were solving, and the tooling did not yet have a category for the answer.
Nine months after the 2025 build, Memory-Augmented LLM Agents and the Resurface of Forgetting (Apr 2026) named the failure mode: under a limited context window, old and new experiences compete for retrieval slots, and the familiar shape of catastrophic forgetting comes back wearing different clothes, exactly what the 2025 substrate had been built to head off before the paper made it legible. Their negative result is uncomfortable to face: under a limited context window, old and new experiences compete during retrieval. The continual-learning bottleneck does not disappear; it relocates from parameter updates to memory access. Add more memory, the competition gets worse. Use a better embedding, you cluster the wrong things together faster.
The headline 30% forgetting-reduction claim is the target of the upcoming contextnest-bench cycle, not a shipped number; this post covers the 2025 design, why the bet was the right shape, and the honest part of where it sits before the benchmark closes. We are publishing the design because the design is testable.
The premise the paper kills
If you have built an agent with retrieval-augmented memory in the last two years, the mental model probably looks like this:
new experience → embed → store in vector DB → retrieve top-k on next queryThe implicit claim is that the embedding space and the retrieval policy together solve the stability-plasticity dilemma. Old memories stay accessible, new memories accumulate, the model never has to update its weights. Continual learning becomes a storage problem.
The Memory-Augmented LLM Agents paper runs the experiment carefully across ALFWorld and BabyAI sequential-task suites and finds the opposite. As memory accumulates:
- Retrieval interference grows. Semantically adjacent old and new entries compete for top-k slots. The newer entry usually wins because it has a sharper embedding profile, but it loses the conditional context that made the older entry useful.
- Context-window pressure becomes the actual constraint. The k in top-k is bounded by tokens, not by storage. As the memory store grows, the effective k shrinks relative to the relevant tail.
- Provenance flattens. A flat vector store has no notion of “this memory is the consolidated form of fifty earlier observations” vs. “this memory is a one-off.” Both look like single rows. Retrieval treats them identically.
Vector DBs deliver state-of-the-art representation; they have almost no organization, and that (representation × organization) gap is the load-bearing framing the paper introduces. Representation is how a memory is encoded (the embedding, the metadata, the typed fields). Organization is how memories relate to each other: clusters, hierarchies, dependencies, derivation chains.
Continual learning in memory needs both.
What attractor consolidation actually is
The response we built does not replace the vector store; it sits on top of it as the organization layer. The unit of organization is an attractor basin: a region in the embedding space with a center, a depth, a radius, and a shape, that pulls related observations toward it as they arrive. Important observations become persistent attractors. Noise decays. Retrieval no longer scans flat rows; it queries the basin topology.
The substrate is a neural field — a continuous high-dimensional space where new observations enter as field excitations and get pulled toward whatever attractors are nearby. The vocabulary is from dynamical systems theory; Unveiling Attractor Cycles in Large Language Models applies the same lens to LLM-internal iterative processes (paraphrasing, in their setup; memory consolidation in ours).
In ContextNest the core type lives in src/context/attractor_dynamics.rs and looks, in skeleton, like this:
pub struct AttractorBasin {
pub id: String,
pub center: Vec<f32>, // basin center in high-dim space
pub depth: f32, // strength of attraction
pub radius: f32, // scope of influence
pub shape: BasinShape, // see below
pub dynamics: BasinDynamics, // attraction curve, evolution params
pub associated_patterns: Vec<String>,
pub health: BasinHealth,
pub created_at: DateTime<Utc>,
pub last_modified: DateTime<Utc>,
}Two things in this struct do not appear in a vector-store row. The shape field encodes that not all concepts have the same geometry in the embedding space. The health and dynamics fields encode that an attractor is a thing that lives, not a thing that is written once. A basin’s depth grows when it absorbs reinforcing observations, shrinks when its surroundings drift, and gets re-shaped when its associated patterns expand into a different region.
The pipeline a new observation goes through:
flowchart TB
OBS([new observation]) --> IMP[assess importance<br/>signals + context]
IMP --> GATE{importance ≥<br/>threshold?}
GATE -- no --> DECAY[decay into the field<br/>no persistent attractor]
GATE -- yes --> NEIGHBOR{nearby existing<br/>basin?}
NEIGHBOR -- yes --> ABSORB[merge into basin<br/>update depth + shape]
NEIGHBOR -- no --> FORM[form new basin<br/>derive shape from cluster]
ABSORB --> CONSOLIDATE[multi-resolution<br/>cross-level update]
FORM --> CONSOLIDATE
CONSOLIDATE --> HEALTH[record health metric<br/>+ evolution event]
HEALTH --> AVAILABLE([available to retrieval])
AVAILABLE --> RETRIEVE[query-time:<br/>walk basin topology<br/>not flat rows]
RETRIEVE -.feedback.-> IMP
classDef gate fill:#7a5a1f,stroke:#fff,color:#fff
classDef alloc fill:#1f3a7a,stroke:#fff,color:#fff
classDef serve fill:#1f5e3a,stroke:#fff,color:#fff
classDef store fill:#4a1f7a,stroke:#fff,color:#fff
class GATE,NEIGHBOR gate
class IMP,ABSORB,FORM,CONSOLIDATE,RETRIEVE alloc
class OBS,AVAILABLE serve
class HEALTH,DECAY storeThe load-bearing piece is the dotted feedback arrow from retrieval back into importance assessment: a basin that keeps getting queried gets reinforced; one that stops decays into the field. Blue is orchestration, yellow the gates, green the served output, purple the persistent state (the basin topology and the health metric that drives decay).
Why basin shape is not always a sphere
A spherical basin is the default, and wrong for most concepts. Here is the shape enum, lifted verbatim from the codebase:
pub enum BasinShapeType {
Spherical, // uniform attraction in all directions
Ellipsoidal, // axis-stretched — direction matters
Hyperbolic, // saddle point — attracts on some axes, repels on others
Manifold, // complex curved surface
Fractal, // self-similar at multiple scales
Adaptive, // shape evolves with learning
}
A spherical basin works when the concept is roughly the same in every direction from its center. “User prefers dark mode” is a spherical fact — its similarity to nearby observations is symmetric. An ellipsoidal basin works when one axis matters more than another. A user’s preferences about tone (formal vs. casual) are nearly orthogonal to preferences about length (terse vs. verbose); flattening both axes into one similarity score loses signal that an ellipsoid recovers.
The hyperbolic case, a saddle point that attracts along one axis and repels along another, delivers a negative-organization signal that is structurally invisible to a flat vector store. “User wants short answers” attracts further short-answer observations and repels observations of the user accepting long answers — they belong to a different basin. The store sees a high cosine similarity between two observations and shrugs; the attractor topology sees a saddle and routes the observation to the correct neighbor basin instead of mixing both into the same retrieval.
Carrying six shapes instead of one costs only a few extra bytes per basin and a parameterized similarity function, and the recall gain shows up specifically on the cases vector stores get wrong. Fractal basins handle nested concepts where the same pattern repeats at different scales; adaptive basins are basins whose shape is itself a learned parameter, updated by the consolidation pass.
Multi-resolution: the hierarchical part
A second piece of structure that does not appear in flat stores: basins live at multiple resolutions, with explicit cross-level connections.
pub struct MultiResolutionStructure {
pub levels: usize,
pub level_params: Vec<ResolutionLevel>,
pub cross_level_connections: Vec<LevelConnection>,
}
pub enum LevelConnectionType {
TopDown, // coarse basin influences finer ones
BottomUp, // fine basins compose into coarse ones
Bidirectional,
Lateral, // within a resolution level
}The model is: a coarse-grained basin like “user is debugging memory issues” lives at level 2; the fine-grained basins like “user tried mem0”, “user looked at AgeMem”, “user benchmarked LongMemEval” live at level 5 and connect bottom-up to the level-2 basin. A retrieval at level 2 returns the coarse concept and walks down to the relevant fine-grained children. A retrieval at level 5 returns a specific fact and walks up to its parent for context.
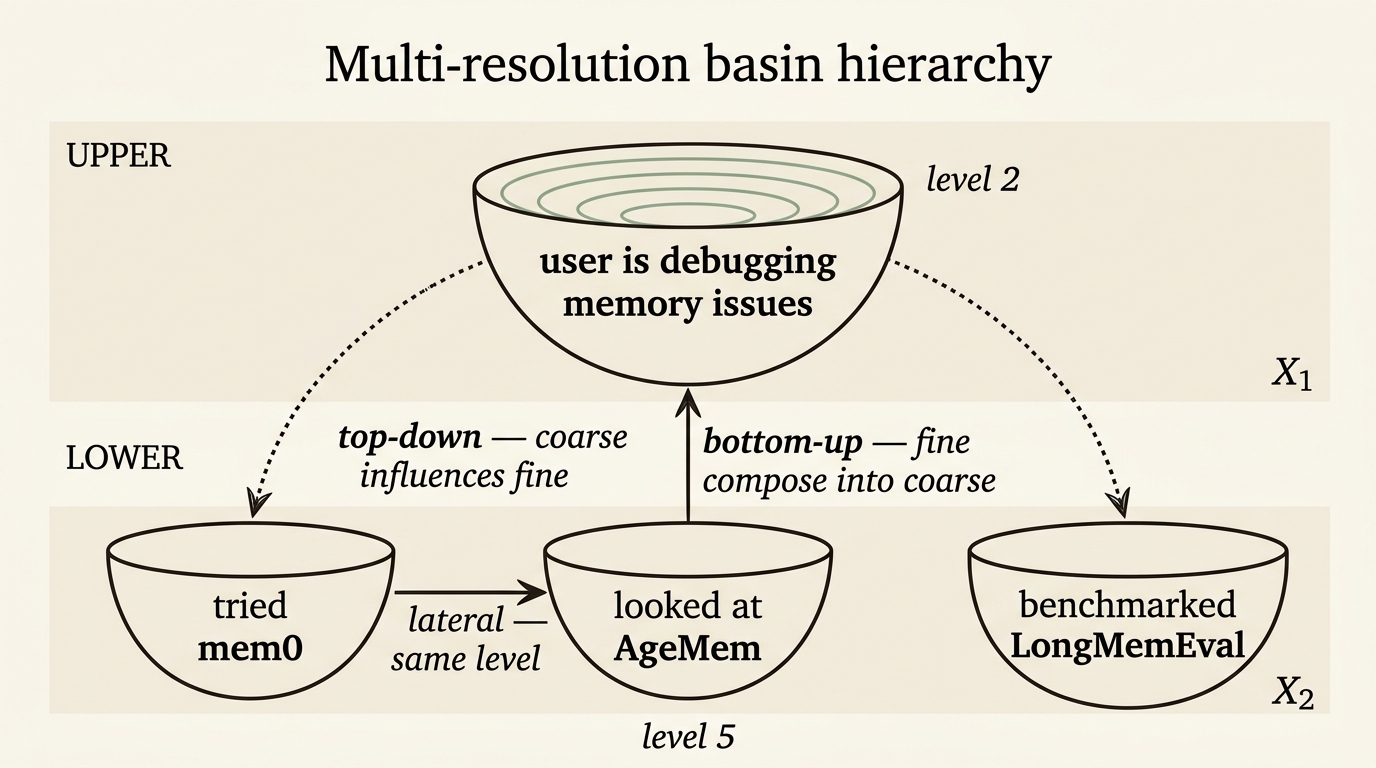
This is what flat stores lose when they collapse hierarchical knowledge into a single embedding pool. Mem0’s add/update/delete/noop operation typing recovers part of the lost structure — it lets you say “this UPDATE supersedes this prior fact” — but it cannot say “this fact composes upward into a coarser concept that lives at a different resolution.” The multi-resolution structure is what makes that composition first-class.
All of this structure, the shapes, the resolution levels, the cross-level edges, is exposed through a single small public interface that every other ContextNest subsystem calls when it wants to add or retrieve a memory.
The MemoryOrchestrator on top
The orchestrator that consumes all of this is small, much smaller than the math under it. The full surface for adding a memory:
pub fn add_interaction_with_attractors(
&mut self,
session_id: &str,
interaction: Interaction,
embedding: Vec<f32>,
importance_signals: ImportanceSignals,
) -> ContextNestResult<Option<String>> {
let cell = self.get_or_create_cell(session_id);
cell.add_interaction(interaction.clone())?;
let importance = self.attractor_field.assess_importance(
&interaction.content,
&format!("session:{}", session_id),
&importance_signals,
);
let attractor_id = if importance > self.persistence_params.importance_threshold {
Some(self.attractor_field.form_attractor(
interaction.content,
embedding,
importance,
&self.persistence_params,
)?)
} else {
None
};
self.maintain_attractor_field()?;
Ok(attractor_id)
}The orchestrator stays small because the structure under it does the work, and three implementation choices make this hold. First, every observation goes through both the conventional memory cell (the retrievable row) and the importance gate. Vector retrieval keeps working for the long tail; attractor consolidation only kicks in for things that crossed the threshold. Second, the threshold is a parameter, not a hardcoded constant, so a chatty domain (conversation) gets a higher threshold than a high-signal domain (code edits). Third, maintain_attractor_field runs on every insertion, so the consolidation pass — decay, basin merging, health update — happens incrementally instead of in a nightly batch.
The honest part — what we have shipped vs. what we have claimed
The architecture is shipped and on main; the performance claim is not, and the two are easy to conflate in a post like this. The basin types, the orchestrator, the importance gating, the multi-resolution structure, the field-coherence-weighted consolidation, are all exercised by the unit suite.
The headline target — ContextNest’s field-coherence-weighted attractor consolidation reduces forgetting by ≥ 30% vs. vector-store and Mem0-style baselines, at comparable token cost, on LoCoMo + LongMemEval-S + ALFWorld + BabyAI sequential-task suites — is the design’s stated bet. The benchmark suite that will measure it (contextnest-bench) is being built alongside contextnest itself; the headline number arrives when those benchmarks run end-to-end, not before. We took the unusual step of publishing the architecture before the benchmark partly because the design is testable in public, partly because the alternative (wait twelve months and publish only the favourable headline) is the engineering version of file-drawer bias.
What we can commit to before the benchmark closes:
- The architecture is falsifiable. If attractor consolidation does not beat vector-store baselines on the same tasks at comparable token cost, the design loses. There is no “yes but” escape: the (representation × organization) axes the paper introduced are the same axes the comparison runs against.
- The architecture is incrementally adoptable. The MemoryOrchestrator is a drop-in for any agent that currently uses a vector store; it shares the same retrieval surface, only the consolidation pass is new. Adopters can A/B test on their own workload long before the headline number lands.
- The architecture is canon-aligned. Every primitive in
src/context/maps to a module in David Kimai’s Context Engineering canon: atoms, molecules, cells, organs, neural fields, attractor dynamics, persistence and resonance, multi-agent systems. That is not the same as being right, but it is evidence the design is not arbitrary.
What falsifiability commits to is equally a map of what it deliberately excludes: the three properties above hold only inside a scope, and that scope has hard edges.
What we are not solving
Attractor consolidation does not address multi-tenant isolation, multi-agent write conflicts, right-to-be-forgotten cascades, or outcome-driven memory value, and each is a deferred decision rather than an oversight.
- Multi-tenant isolation. The basins are per-user / per-scope today; cross-user knowledge transfer needs an ACL layer this design has not specified.
- Multi-agent write conflicts. When two agents in the same scope try to consolidate contradictory observations, the resolution path is undefined. Single-user single-agent is the v0.1 scope.
- Right-to-be-forgotten cascade. Basin deletion has to invalidate downstream summaries that descended from the deleted observations; that machinery exists in the substrate but the GDPR-compliant cascade is a v0.2 line item.
- Outcome-driven memory value. A basin’s health metric today is structural (depth × radius × coherence). It is not yet outcome-aware — whether retrieved memories actually improved downstream task success. That signal is the next obvious upgrade once the benchmark loop is live.
Naming them in the architecture post is part of staying honest about the bet.
The deferred list is also a readout of the axes any memory substrate has to take a position on, and those axes stay in play regardless of whether the attractor consolidation benchmark lands at the 30% target or falls short.
What to take from this regardless of who wins
External memory does not escape continual learning’s stability-plasticity dilemma, and that is the durable contribution of 2604.27003, regardless of whether attractor consolidation hits its 30% target. Anyone shipping a long-running agent with a vector-store memory layer is making an implicit bet that retrieval interference will not bite their use case before someone builds the better memory layer. The bet is now legible. The benchmarks are now public.
If you are building a long-running agent today, audit your memory layer’s organization, not its retrieval, its organization: ask whether you can name the difference between a noise observation and a consolidated one, and whether two observations that point in the same embedding direction but belong to different basins are distinguishable. If the answer to either is “no, they all look like rows to me,” the paper says you are sitting on the bottleneck whether you have hit it yet or not.
The attractor basins are our bet on what that organization layer looks like. The benchmark results will tell us whether the bet was the right one. We will write the follow-up either way.
Comments
Sign in with GitHub to leave a comment. Threads live on SourceShift/blog-comments — moderated.