Two prompt frameworks, one runtime: how we adopted BAML without giving up our cost ledger
Adopt a typed-LLM framework (BAML, Instructor, DSPy, Outlines, the Vercel AI SDK with Zod) and the first decision feels like which layer of your stack to surrender. These frameworks ship integrated clients that wrap the network call to give you typed parsing, per-field streaming, and a playground that iterates prompts faster than anything you had. They also collide head-on with whatever existing layer your project uses for cost tracking, idempotency caching, retry policy, and tracing. Most teams pick one and live with the loss.
That framing — which framework wins — turns out to be the wrong question. The deeper framing, made explicit in Hanlin & Chan’s 2026 work on Runtime Burden Allocation, is that structured LLM output is a systems-level burden-allocation problem: the question is not which framework owns the call, but where in the generation stack structural work gets done — emitted directly by the model, compressed during transport, or reconstructed locally after generation. Once you see the problem that way, the right answer almost never comes out as “one framework owns everything.”
The design we ended up with — BAML in “modular mode”, rendering and parsing but never touching the wire — sits beside an in-house prompt harness (registry + four-tier resolver + execution ledger) that records the resolved prompt’s stable hash, model, cost, latency, trace, and per-objective outcomes for every call. The harness sits beside a separate context-engine substrate that owns feature-level composition; both are in-house investments the integrated-client pattern would silently absorb. The pattern works, but it took a year to feel right, and we did not have the language for why it works until the literature gave us one.
The framing: burden allocation, not framework adoption
Hanlin & Chan run a 48-configuration full-factorial benchmark on structured routing across OpenAI, Gemini, and Llama backends — 15,552 requests in total — and recover a result that lands hard: there is no universal best mode for structured output. Backend × mode interaction is the dominant statistical effect, with partial η² ≈ 0.96 on routing accuracy — on the same scale as the backend main effect itself. A compressed-local-reconstruction package that holds up on Gemini and OpenAI (token cost drops 60–65%, accuracy drops 23–27 points) collapses on Llama, where format compliance falls to 53% and routing accuracy to 22.8%.
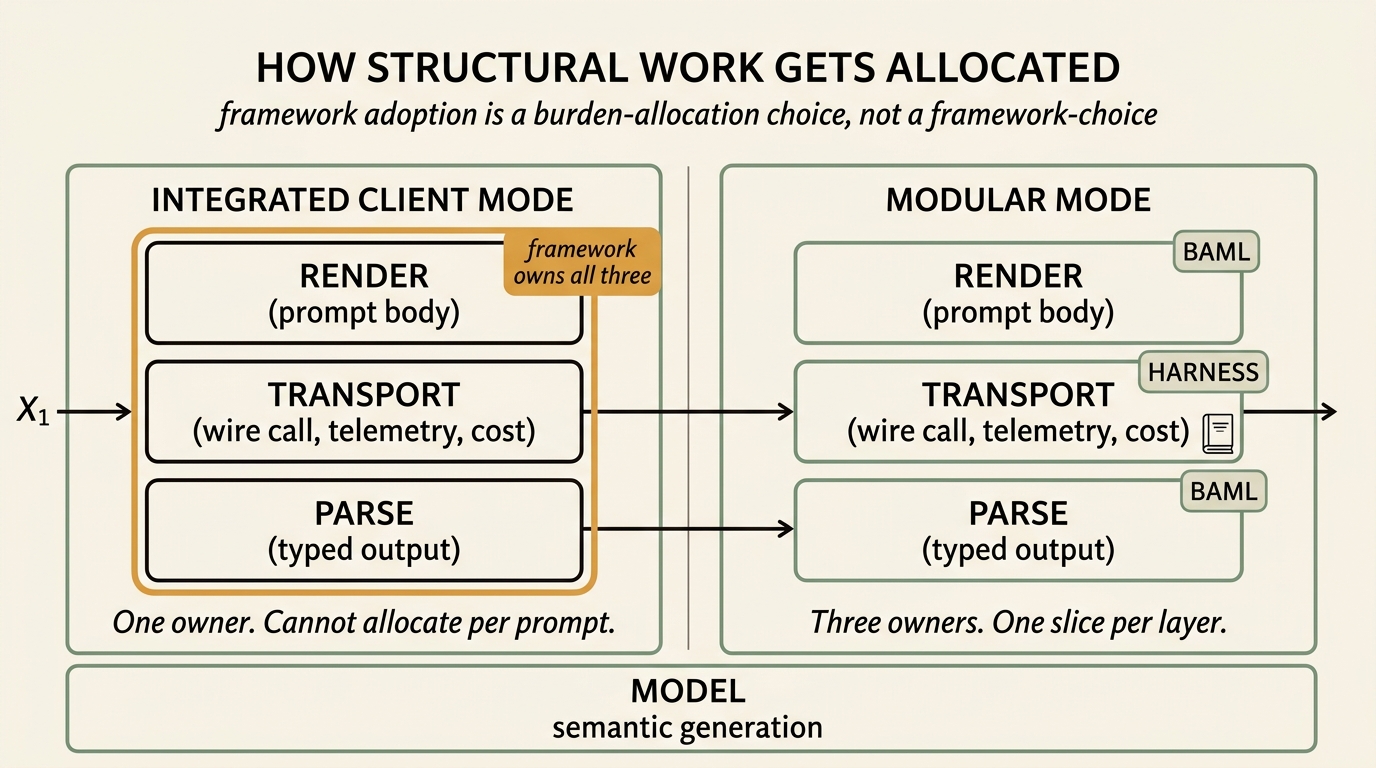
Two adjacent literatures converge on the same prescription: split the integrated-client bundle back into render, transport, and parse, and let your existing infrastructure own each job independently. LLM-Rosetta argues against O(N²) bilateral adapters between providers and proposes a hub-and-spoke intermediate representation — separating the typed-IR layer from the wire-translation layer. Making Prompts First-Class Citizens for Adaptive LLM Pipelines argues prompts should not be opaque strings disconnected from pipeline logic but should expose their structure to the surrounding observability and optimization layers.
Why this is normally posed as either/or
BAML’s default integrated client — render, network, parse as one wire-owning unit — collides with whatever layer your project already uses for cost tracking, idempotency caching, retry policy, and tracing. The DSL itself lets you declare a function with input parameters, an output class with typed fields and per-field descriptions, and a streaming policy; the generated client in your host language owns the entire call by default. The pitch is real and the tooling is excellent. The friction is that ownership boundary.
The same tension shows up across the structured-output ecosystem, with different framings of the same trade.
| Framework | What it wants to own | Where it collides with house infrastructure |
|---|---|---|
| BAML | The render-parse-stream loop, optionally the call itself | Cost trackers, OTel spans, idempotency caches that wrap the LLM client |
| Instructor (Python) | The Pydantic-validated response | Your retry/timeout policy on the openai/anthropic client |
| DSPy | The prompt body via teleprompter optimization | Static prompt templates, manual prompt edits, your prompt-version ledger |
| Outlines / Guidance | The token-level generation loop | Whatever wraps streamed deltas in your app (cancellation, partial render, OTel) |
| Vercel AI SDK + zod | The fetch + the Zod parse | Provider-specific quirks your existing wrapper already handles |
Surrendering to one framework’s integrated client has a specific cost: the ability to allocate render-vs-transport-vs-parse responsibility independently per prompt. Most teams pay it anyway — they pick a framework, let it own the wire, then layer thin telemetry on top. That works when the team is starting fresh. It does not work when your harness already records hash, cost, latency, trace, and per-objective outcomes per call and your dashboards are tuned to those fields.
We wanted both. The BAML authoring experience (typed fields, per-field streaming, a playground that iterates prompts faster than anything we had) and the harness’s resolver + ledger + tracing. The way we kept both is the part that took the most thought.
Modular mode: the design
BAML offers an undocumented-but-supported way to use the framework without giving it the wire. The client exposes two surfaces independently:
request.X(args)renders the prompt body and returns it as a string. No network call.parse.X(text)takes a model response string and parses it into the typed output. No network call.
If you call those two without calling the integrated b.X() (which would do everything), BAML is reduced to a typed prompt renderer and a typed response parser, sitting on either side of whatever wire layer you already have. In burden-allocation terms: BAML owns the structural-reconstruction slice; the harness owns the transport slice; the model owns the semantic-generation slice. Each layer is replaceable independently.
That is the whole trick. The hybrid call site looks like this:
// Feature flag per prompt; defaults to legacy path
if (BAML_ENABLED_FOR_THIS_PROMPT) {
try {
// 1. BAML renders the typed prompt. No network call.
const req = await bamlClient.request.GenerateImageBriefAndCaption(input1, input2);
const renderedPrompt = req.body.json().contents[0].parts[0].text;
// 2. The existing gateway owns the wire, cost, retries, OTel span.
const resp = await llm.generate({
prompt: renderedPrompt,
costTracking: { feature: 'image_brief', traceId },
});
// 3. BAML parses the response. No network call.
return bamlClient.parse.GenerateImageBriefAndCaption(resp.text);
} catch {
// 4. Any failure falls through to the legacy harness + Zod path.
}
}
// Legacy: harness resolves prompt text, gateway calls, Zod parses.
return legacyPath(input1, input2);Four pieces, in that exact order, plus a feature flag that lets the call site flip between BAML and the legacy harness without code change.
flowchart TD
CALL([feature call site]) --> FLAG{BAML enabled<br/>for this prompt?}
FLAG -- no --> LEGACY[harness 4-tier resolver<br/>document · user · env · default]
LEGACY --> WIRE
FLAG -- yes --> BAMLREQ[BAML request.X<br/>renders typed prompt]
BAMLREQ --> WIRE[gateway: wire call<br/>+ OTel span + cost ledger]
WIRE --> RESP[model response text]
RESP --> BAMLPARSE{BAML enabled?}
BAMLPARSE -- yes --> BAMLPAR[BAML parse.X<br/>typed output]
BAMLPARSE -- no --> ZODPAR[legacy Zod parse]
BAMLPAR --> OUT([typed result])
ZODPAR --> OUT
WIRE -.cost row.-> LEDGER[(prompt_executions ledger)]
classDef gate fill:#7a5a1f,stroke:#fff,color:#fff
classDef alloc fill:#1f3a7a,stroke:#fff,color:#fff
classDef serve fill:#1f5e3a,stroke:#fff,color:#fff
classDef store fill:#4a1f7a,stroke:#fff,color:#fff
class FLAG,BAMLPARSE gate
class LEGACY,BAMLREQ,WIRE,BAMLPAR,ZODPAR alloc
class CALL,RESP,OUT serve
class LEDGER storeCost tracking is the design’s load-bearing invariant: the ledger does not care which path rendered the prompt, only that a string was rendered and a model responded. The yellow gates are where the per-prompt feature flag steers traffic. Blue is where the work happens, with the wire-and-cost box deliberately in the middle: both paths feed it, neither owns it. Green is the surface the caller sees.
Canary-style monitoring during migration comes from tagging every call with promptSource: 'baml' | 'legacy' and parserSource: 'baml' | 'regex' | 'zod'. If the BAML branch’s quality drifts from the Zod baseline, the difference shows up in the dashboard within hours.
Which prompts to actually migrate
Not every prompt benefits. BAML’s value is in the typed structured output with per-field streaming behavior; for a one-liner that returns a single string, the wrapper adds noise without adding type safety. The burden-allocation framing predicts this: if structural work is trivial (a single string field), moving the structural-reconstruction slice from the harness’s Zod path to BAML’s typed parser does not change much. We wrote a filter that survives a 5-second skim:
| Migrate (high ROI) | Skip (low ROI) |
|---|---|
| Multi-field structured output (≥2 typed fields) | Single-string output (BAML wraps as class { result string }, pointless) |
| Free-form text from a model that lacks JSON-mode (e.g. preview image models) | One-off prompts unlikely to change |
| Per-field streaming behavior matters | Prompts that operate on prompt text itself (orthogonal to BAML’s value) |
| Prompt iteration is bottlenecked by edit-restart cycle (BAML playground is roughly 20× faster) | Prompts already humming along on the harness with no pain |
Migrate when iteration is the bottleneck — the DSPy literature makes the same case from two angles, and our filter is its engineering reduction. Is It Time To Treat Prompts As Code? (arXiv:2507.03620) studies five use cases and finds the win is biggest when prompts are subject to optimization loops, not when they are written once and forgotten. Optimizing LLM Prompt Engineering with DSPy Based Declarative Learning (arXiv:2604.04869) lands on the same conclusion from the opposite end: declarative authoring beats heuristic trial-and-error specifically when the prompt is iteratable.
Where the literature lands on this
The per-prompt feature flag in the call site is not paranoia; it is the granularity the systems-level evidence prescribes. Hanlin & Chan’s effect-size finding — backend × mode interaction at partial η² ≈ 0.96, on the same scale as backend choice itself — means that the right packaging for a given prompt is materially different from the right packaging for the next prompt, even on the same model. A framework-wide opt-in to BAML’s integrated client is the wrong control: it pre-commits every prompt to one burden-allocation profile across all backends and all output shapes. The per-prompt flag preserves the choice where it actually matters.
The try/catch fallback is the second piece of evidence-grounded design. PromptPort formalizes “format collapse” — the failure mode where a prompt that returns clean JSON on one model produces fenced or prose-wrapped output on another, defeating strict parsers. PromptPort’s prescription is a reliability layer between the framework parser and the model output. The catch block here falls into that role: BAML’s typed parser is the primary path; the Zod-backed harness is the recovery layer. This is not over-engineering, it is the literature’s recommended shape for the format-compliance problem that any structured-output framework will eventually hit.
What the literature does not say is that this exact pattern is universally best. It says that no universal best exists — that the right design is conditioned on backend, prompt shape, and which infrastructure you already have. For projects without an existing harness, the integrated-client bundle is the simpler shape, and the literature does not contradict that choice. For projects with a year of tuned dashboards, modular mode is the form burden allocation takes when “preserve the existing observability investment” is a hard constraint.
Modular mode preserves what you built, but splitting three jobs across two frameworks opens seams the integrated client never had — two of those seams are still open in our implementation, and they are worth naming before you ship.
What this didn’t solve
Two honest caveats worth carrying.
The optimization loop bypasses the ledger. Our prompt-evolution engine reads from the prompt_executions ledger to find candidates for the next generation of improvements: which prompts had high cost, low rubric scores, surprising failure modes. When the BAML branch fires, the ledger still gets the cost row (because the gateway writes it), but it does not know the prompt body came from a BAML template rather than a harness-registered string. For the evolution loop to operate on a BAML-managed prompt, the hybrid call site has to explicitly write a synthetic execution row referencing the canonical BAML body. We have not wired that yet. It will matter the first time we want the evolution loop to improve a BAML-managed prompt; right now the BAML-managed prompts are stable enough that nobody has asked. The Prompts-as-First-Class-Citizens literature names this exact gap: when prompts are bound to a framework’s typed authoring, they need an explicit affordance to expose their structure back to the pipeline’s optimization layer. Ours is a TODO.
Admin override semantics are partial. The harness’s four-tier resolver lets an administrator override any registered prompt for a specific document, user, or environment. The override lands as a row in the prompt-version table and the next call picks it up. For BAML-managed prompts, the admin UI shows a “managed by BAML” badge and accepts the edit, but the runtime still uses the BAML template, not the edit. The recipe documents this as “admin-UI visibility, not full override semantics.” Worth flagging if anyone expects to hotfix a BAML prompt via the admin UI. The fix is straightforward in principle (resolve BAML overrides through the same four-tier cascade) and untouched in practice, because the BAML-managed prompts are the ones we are happiest with and least frequently want to override.
Both gaps are bounded and documented, which puts the design in a state where the trade-offs are legible — and that legibility is exactly what makes it possible to say clearly when the pattern applies and when the integrated client is the better call.
When to reach for this design
If you have an existing prompt-management layer with non-trivial telemetry, cost tracking, or version control, and you want BAML’s typed authoring and parser without ripping out the existing layer, modular mode is the path. The exact shape is small enough that we have copy-pasted it across two services so far and could plausibly templatize it. The burden-allocation lens makes the engineering decision clearer: you are not picking BAML over the harness, you are letting each layer own the slice it is best at.
If you do not have an existing prompt-management layer, just let BAML own the wire. The integrated client is excellent and the layer of indirection in modular mode is not worth it for greenfield projects. The same burden-allocation framing tells you why: with no existing observability investment to preserve, the integrated bundle is the simplest allocation of structural work — and simplicity beats principle when there’s nothing to lose.
The signal that you need this pattern is the conversation: when someone proposes adopting BAML and someone else points out it will collide with the cost dashboard, the answer is not “pick one.” The two frameworks are not competing for the same job; the integrated client is just an opinionated default that bundles three jobs — render, transport, parse — into one wire-owning shape that the burden-allocation framing tells us was never the right boundary. Splitting them back out is a small amount of code and a meaningful preservation of the infrastructure you already paid to build. The 2026 literature now provides the vocabulary for why that split is the principled choice rather than just a pragmatic compromise.
Comments
Sign in with GitHub to leave a comment. Threads live on SourceShift/blog-comments — moderated.