The chapter that forgot why it existed
Even with a perfect chapter plan and plenty of context headroom, an LLM agent can forget its own objective mid-task. Twelve sections, every claim backed by a retrieved source, the tone matching the user’s preference profile. Then the agent hit section seven — a dense methodological comparison — and quietly dropped the original objective. By section nine it was summarizing papers that had nothing to do with the book’s thesis. By section eleven it was inventing citations.
The prompt hadn’t changed. The context window was barely half full. The agent simply no longer knew why it was writing.
This is the failure mode that made me stop treating LLM agents as “a model with more context” and start building a world model instead.
The loop that should have been there
Most agent papers converge on the same shape. SimuRA (2507.23773) calls it simulative reasoning — evaluate before acting. Dyna-Think (2506.00320) unifies it as reasoning + acting + world-model simulation. The practical version is an eight-step loop:
observe → retrieve → plan → simulate → execute → verify → reflect → store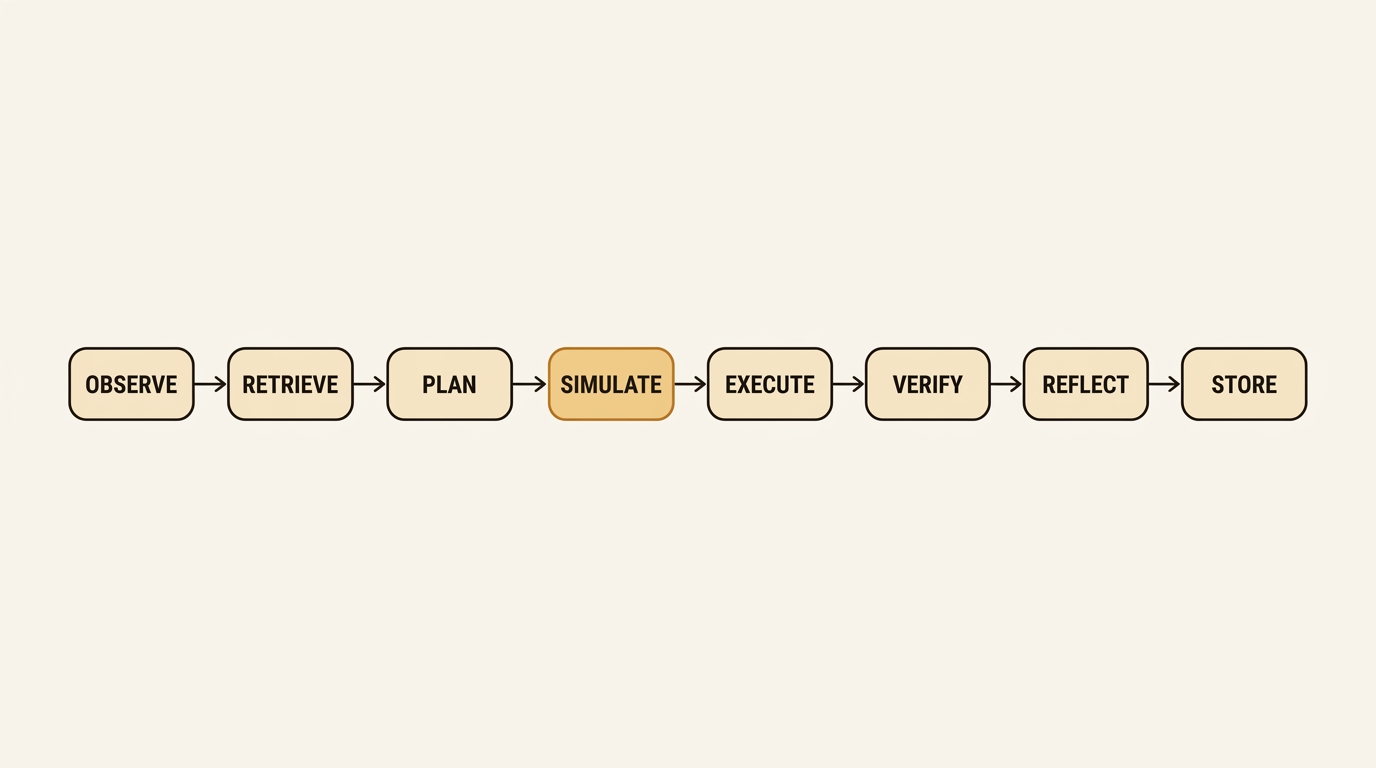
The step everyone skips is simulate. An agent without simulation treats the LLM as both planner and execution environment. It generates a plan token-by-token, but it has no separate representation of “if I take this action, what state should change?” So when the generated text drifts — and it always drifts on long-horizon tasks — the system has no mechanism to detect the divergence until the output is already wrong. The Structured Cognitive Loop (2511.17673) formalizes the missing piece as Control — a governance layer between reasoning and execution.
The loop tells you when to simulate, but it does not tell you what concrete structure survives across those steps to keep the agent anchored to its goal — which is exactly what a world model provides.
What a world model actually buys you
A world model is a runtime state capsule that the agent can inspect, hash, and compare against expected outcomes before calling the model. It is not a bigger prompt or more retrieved documents stuffed into the context window.
When my system plans a chapter, the world model holds:
- the user’s original objective (not just the prompt text, but the success criteria)
- the evidence that has already been used (so the agent doesn’t double-dip or contradict itself)
- the constraints that are still active (style, length, forbidden claims)
- the expected state change for the next action (what should be true after this step that wasn’t true before)
- the verification gate that must pass before persistence
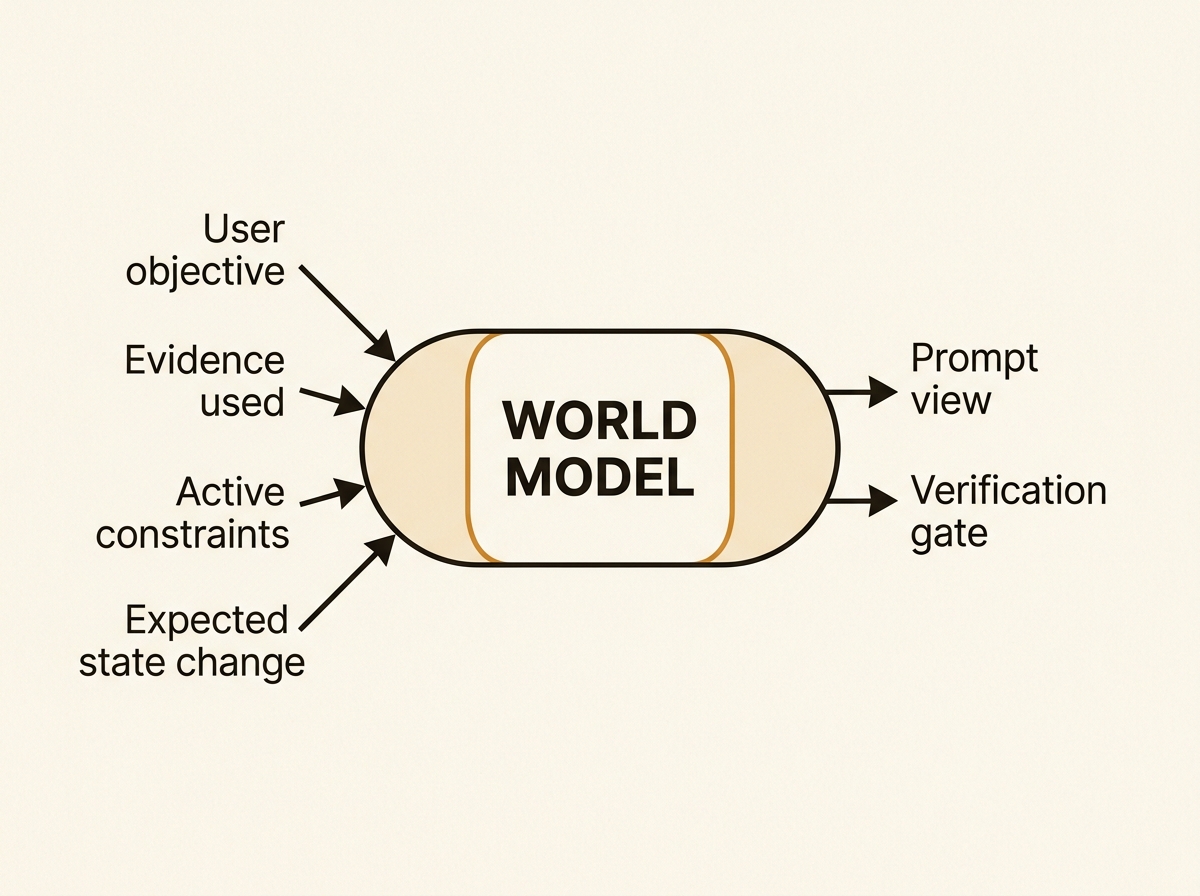
This is what the retrieval-augmented world model literature (2510.11892) gets right: LLM world models hallucinate less when they ground their simulation in retrieved factual context. The world model doesn’t replace retrieval; it uses retrieval to check its own predictions.
The neuro-symbolic hybrid approach (2602.10480) pushes this further. LLMs provide semantic flexibility; symbolic models provide deterministic transition compliance. For the critical steps — state transitions, verification gates, memory promotion — I use explicit structured checks. The LLM handles the creative steps (drafting prose, synthesizing arguments). The symbolic layer handles the steps where a mistake is expensive (persisting a chapter, marking verification passed, promoting memory).
A state capsule is only useful if it stays faithful to reality, and keeping it aligned as the system acts turns out to be the harder problem.
The co-evolution problem
The hardest part of a world model is keeping it aligned with reality as the system acts.
CoEx (2507.22281) identifies the static-world-model problem: agents rely on pretrained world models that drift from reality as environments change. In my system, every execution step produces an observation — the actual output, the actual state change, the actual verification result. The reflection step compares expected vs actual. If they diverge, the world model updates. If they diverge consistently, the system flags a pattern for human review.
Reinforcement world model learning (2602.05842) frames this as action-conditioned prediction: the agent learns to anticipate consequences by training on its own simulated transitions. I don’t train a separate model for this; I use the same LLM in a simulation mode, with the prompt harness locked to read-only tools and a deterministic temperature of zero. The simulation is slower than the real execution, but it catches the “section seven drift” before a single word gets persisted.
Alignment is necessary, but the practical payoff comes from inverting how you think about prompts entirely.
The practical rule
If information matters for behavior, put it in the world model first and render the prompt view from that state. Prompt text should be a view of the state, not the only place where state exists.
This inverts the usual LLM-agent architecture. Most systems start with the prompt: “You are a helpful writer, here is the context, please generate chapter seven.” The prompt grows until it hits the context limit, then the system adds context-window management as a band-aid.
When this architecture is missing, the symptoms are unmistakable — and they look exactly like a context problem.
Detection fingerprint
If your agent drifts or hallucinates mid-task, you have a state-management problem, not a context problem. The fix is an explicit state capsule that survives across model calls, not a longer prompt that gets truncated on the next turn.
Comments
Sign in with GitHub to leave a comment. Threads live on SourceShift/blog-comments — moderated.