The agent is not a transaction
The default contract of an LLM agent is a transaction. You submit the request. The agent works in isolation. You sit on a spinning indicator. When the agent eventually returns — fifteen minutes later, twelve tool calls deep — you either accept the result or kill the process and start over. There is no middle option. The user’s choice is binary: wait or restart.
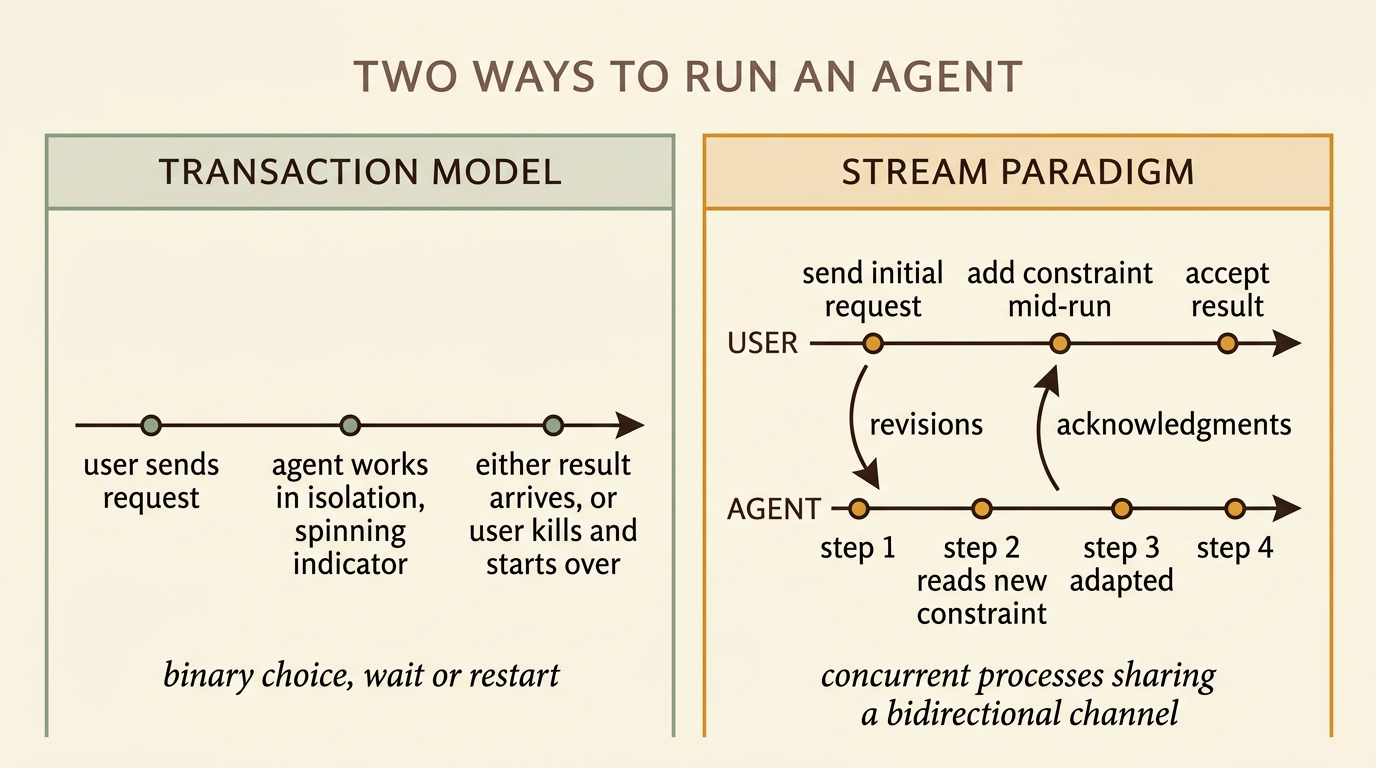
We had been building agent runs in LibWit for six months when we noticed that this contract did not match what readers actually wanted. A user kicking off a forty-minute research run wanted to add a constraint at minute eight, not to discover at minute forty that the early steps had drifted off-topic. A user pausing a chapter-generation run before a long meeting wanted to come back two hours later and pick up where the agent left off — not start the whole thing over because the sandbox had been torn down for tidiness. Both wishes were structural mismatches against the transaction model.
The fix turned out to be two changes that compose: durable agent state with a checkpoint column the executor writes on every meaningful turn, and a stop-don’t-destroy policy on the sandbox layer that gives every agent run a thirty-day window in which it can be resumed. A separate mid-flight steering channel lets a user inject a revision while the agent is still running, instead of having to wait for completion before correcting it. Neither change required a new framework. Both required us to stop treating an agent run as a function call.
Revisable by Design (Apr 2026) is the paper that finally gave the shape a name. The authors reject the transaction assumption outright and propose the stream paradigm — agent execution and user intervention as concurrent, interleaved processes sharing a bidirectional channel. They prove that an agent’s flexibility is bounded by the reversibility of its action space, and they ship Revision Absorber, an algorithm that matches a brute-force restart’s quality while wasting an order of magnitude fewer steps. The paper landed three months after we shipped the second iteration of our checkpoint format, and reading it was the moment several local decisions stopped feeling like ad-hoc engineering and started feeling like the principled answer to a properly-named problem.
This post is what we shipped, why the shape ended up the way it did, and what the 2026 literature now provides as the vocabulary for why that shape is the right one.
The transaction assumption, named
The transaction model is so default that most agent frameworks bake it into the type signature. Agent.run(input) -> Output returns when the agent decides it is done. The framework owns the loop; the user owns nothing inside it. Interruption is not a first-class concept — it is process-killing. Resume is not a primitive — it is “start a new run, hope the model finds its way back.”
The cost of this default is invisible until your agents run for more than a couple of minutes. Then it bites in three specific shapes — the same three InterruptBench (Apr 2026) formalizes as the interruption taxonomy:
| Interruption type | Example | What transaction-model agents do |
|---|---|---|
| Addition | ”Also include papers from CHI 2026” | Either ignore (already past the search phase) or restart entirely |
| Revision | ”Actually, the chapter should target 8000 words not 6000” | Restart; the early outline used the wrong target and propagated |
| Retraction | ”Skip the multi-language translation step” | Cannot retract a completed step; either accept the cruft or restart |
InterruptBench’s headline finding is that handling these effectively and efficiently across long-horizon tasks “remains challenging for powerful large-scale LLMs” — meaning even strong backbones don’t handle interruption well by default. Their result on six frontier models is uncomfortable to read: every model loses meaningful capability when interrupted, and most lose it the same way (treating the interruption as a new transaction rather than a revision to the in-flight one).
The transaction model is also what makes pause/resume hard. A function call cannot be paused in any useful sense — you can suspend the thread, but you cannot persist its semantic state and restart it from another process. Pause/resume for agents requires the run to be a durable state machine, not a stack frame. That is a different shape from the start.
What we shipped: durable state plus a steering channel
The core change in LibWit was adding checkpoint JSONB to the lw_agent_runs table and teaching the ReAct executor to write it on every meaningful boundary — tool-call result, reasoning step, scratchpad mutation. The shape is roughly this:
// shipped — server/services/agentRun/agentCheckpoint.ts
interface AgentCheckpoint {
// What the executor needs to resume the loop
history: ReActStep[]; // full reasoning + tool-call trace
scratchpad: Record<string, unknown>; // per-run scratch state
// What the sandbox needs to resume the environment
sandbox_id: string; // Daytona sandbox handle
sandbox_state: 'running' | 'stopped';
// What the orchestrator needs to know about progress
current_step_id: string;
step_status: 'pending' | 'running' | 'committed';
// What downstream replay needs
schema_version: number;
saved_at: string; // ISO timestamp
}The non-obvious piece is the split between executor state (the reasoning and scratchpad), environment state (the sandbox), and progress state (the step ID). When a run is paused, the executor state goes to the database, the sandbox is stopped (not destroyed), and the next time the user resumes, the orchestrator reads the checkpoint, restarts the sandbox in place, and replays the executor from the last committed step.

Crab (Apr 2026) — published two weeks after our first checkpoint cut — independently reaches the same partitioning. Their framing names the underlying difficulty as an agent-OS semantic gap: agent frameworks see tool calls but not OS effects, the OS sees state changes but lacks turn-level context. Their measurement is the load-bearing one to take away from the paper: 75% of agent turns produce no recovery-relevant state. Most checkpoints are unnecessary. The interesting questions are when to checkpoint and what to include — not whether to do it.
We do not run Crab; we run a coarser version of the same idea. Our checkpoint is written on every committed step, not every turn, because step boundaries are the units the executor already serializes around. That’s cheap enough at our turn count (small hundreds per run, not thousands) that the eBPF-level optimization Crab does is not yet worth its weight. If we ever push to the thousand-turn regime — multi-day research agents — Crab’s selectivity becomes the obvious upgrade.
The steering channel runs alongside. The executor watches a per-run revisions table at the top of each loop iteration. If a new row is present, the executor reads it, folds the revision into the next prompt, and writes back an acknowledgment row that the FE picks up via SSE. The full cycle from user-types-revision to executor-incorporates-it is sub-second when the executor is between turns, and at most one-turn-latency when it is mid-tool-call. The user does not have to wait for completion to course-correct.
flowchart TD
USER([user starts run]) --> EXEC[ReAct executor loop]
EXEC --> STEP{step boundary?}
STEP -- yes --> CHK[write checkpoint:<br/>history + scratchpad + sandbox_id]
CHK --> POLL{revisions table<br/>has new row?}
POLL -- yes --> FOLD[fold revision into<br/>next prompt]
POLL -- no --> NEXT[next executor step]
FOLD --> NEXT
STEP -- no --> NEXT
NEXT --> EXEC
USER -.adds revision.-> REV[(revisions table)]
REV -.read at next step.-> POLL
USER -.pauses.-> STOP[orchestrator:<br/>sandbox.stop<br/>checkpoint frozen]
STOP -.30-day window.-> RESUME{user returns?}
RESUME -- within 30d --> RESTART[sandbox.start<br/>replay from checkpoint]
RESUME -- after 30d --> GC[sandbox auto-deleted<br/>run terminal]
RESTART --> EXEC
classDef gate fill:#7a5a1f,stroke:#fff,color:#fff
classDef alloc fill:#1f3a7a,stroke:#fff,color:#fff
classDef serve fill:#1f5e3a,stroke:#fff,color:#fff
classDef store fill:#4a1f7a,stroke:#fff,color:#fff
class STEP,POLL,RESUME gate
class EXEC,CHK,FOLD,NEXT,STOP,RESTART alloc
class USER,GC serve
class REV storeBlue is the executor work. Yellow is the gates that decide whether to act on a checkpoint, a revision, or a resume. Green is the user-facing surface. Purple is the revisions table that bridges the two concurrent processes — the run and the user. The dotted lines are the steering and pause-resume edges that turn the agent from a function call into a long-lived process.
Why “stop, never destroy”
The hardest part of pause/resume turned out not to be the executor — it was the sandbox. Most agent frameworks tear down the sandbox after the run completes. The motivation is good (cost, cleanliness, no zombie processes), but it makes resume impossible. If you destroyed the sandbox at minute fifteen, the user returning at minute forty cannot pick up — every shell command’s effects, every installed dependency, every cached intermediate is gone.
Our rule is: stop on failure, stop on pause, stop on completion. Destroy only after a thirty-day grace period. The Daytona platform makes this cheap because a stopped sandbox costs near-zero (no compute, only thin disk and snapshot storage). The thirty-day window is empirical — most resume attempts arrive within forty-eight hours; the long tail is bounded by a month. Past that, the chance the user wants to resume is small enough that the storage cost stops being justified.
The same rule has a second virtue: failed runs become inspectable instead of lost. When something goes wrong, the sandbox is alive with the full filesystem state at the moment of failure. We grep, we read partial outputs, we diff against expected. Then we resume from the last committed step — never from scratch. This is the same principle the project’s “zero fallback” rule encodes: fail explicitly, keep the sandbox alive, inspect, fix, resume.
Operationally this had one early bug worth mentioning. The checkPlanSandboxAlive watchdog was flipping plan jobs to failed within ~250 ms because findPlanSandboxForJob returned null during Daytona’s 10–30 second cold-start. The fix was a SANDBOX_CREATE_GRACE_MS=90s measured from job.startedAt. The lesson: when you are working in a cooperative-stop world, every “is it alive” check needs to know the difference between “not yet” and “no longer.” Defaulting to “no longer” turns transient cold-start latency into terminal failure.
Handling the three interruption types
InterruptBench’s taxonomy maps cleanly onto our steering channel. The handling differs per type because the reversibility differs per type — which is the exact insight Revisable by Design formalizes when it classifies every action as Idempotent, Reversible, Compensable, or Irreversible.
| Interruption | Our handling | Reversibility class of the affected work |
|---|---|---|
| Addition (“also include CHI 2026 papers”) | Fold into next step’s prompt; previous steps stand as-is; the agent’s plan widens. | Idempotent — adding a constraint never invalidates work that already satisfied a stricter constraint set. |
| Revision (“target 8000 words not 6000”) | Fold into next step; emit an explicit re-evaluate prior outline sub-step; agent decides what to redo. | Reversible — outline can be regenerated; word-count target changes the shape without breaking the structure. |
| Retraction (“skip the translation step”) | Cancel the open step if mid-flight; mark the canceled step as retracted in the trace; subsequent steps see the retraction in context. | Compensable — translation can be undone if already started, but compensation has a cost (sandbox state, partial files). |

Two cases the steering channel still cannot handle cleanly:
- Irreversible side effects. If the agent has already sent an email or made a payment, no amount of steering can take it back. We classify any tool that has external side effects as
irreversibleand forbid them from running until a higher trust tier authorizes it. TheRevisable by Designpaper proves a generalization of this: “conflicting irreversible actions make full specification satisfaction impossible.” Our rule is the engineering corollary — don’t let the agent take an irreversible action without explicit user gate. - Stale prompts mid-tool-call. If a tool call is running when the revision arrives, the in-flight call sees the pre-revision prompt. We checkpoint on tool-call completion, not start, so the revision lands at the next executor step. For most tools this is fine. For tools that block for minutes (long shell runs, large file generations), it isn’t. Future work, deferred.
AGDebugger (CHI ‘25) — the first interactive-debugging UI for multi-agent systems — found the same dynamic in their user study: “edit and reset prior agent messages” was the most-used steering primitive across 14 participants. Their finding generalizes to our case. The most-used steering action by LibWit users is not “add new constraint” — it is “edit my prior turn.” Tool support for retroactive editing of the agent’s input matters more than tool support for forward intervention.
What this didn’t solve
Three honest caveats worth carrying.
Cross-run reasoning continuity. When a user pauses a run, comes back two weeks later, and resumes, the executor restarts with the saved scratchpad — but the model has no working memory of why it picked the earlier strategy. If the user has also added revisions in between, the executor has to re-discover its own reasoning from the trace. This is recoverable for short pauses; it degrades on long ones. Adding a resume primer that summarizes the saved trace into a compact prompt is on the list.
Steering granularity below the step boundary. Revisions land at the next executor step, not in the middle of a tool call. Most tools complete fast enough that this is acceptable; some don’t. The Revision Absorber algorithm in Revisable by Design is more aggressive — it can fire at any point and uses an Earliest-Conflict Rollback to repair the trace. Implementing that on top of our existing checkpoint requires a finer-grained checkpoint cadence than every-step. It is the obvious next iteration.
Multi-user steering on a shared run. A run owned by one user has one stream of revisions. A run that a team is collaborating on — multiple users adding constraints concurrently — would need conflict-resolution semantics on the revisions table. We have not designed that. The pattern from Revisable by Design’s reversibility taxonomy is the framing we would start with, but the engineering is unbuilt.
The framing that makes the rest fit
Externalization in LLM Agents (Apr 2026) — a fifty-four-page review of harness engineering — argues that practical agent progress increasingly depends not on stronger models but on better external infrastructure: “memory externalizes state across time, skills externalize procedural expertise, protocols externalize interaction structure, and harness engineering serves as the unification layer.” The checkpoint column + the revisions table + the stop-don’t-destroy sandbox are three different externalizations sharing the same purpose: they take cognitive work the model would otherwise have to do internally — remember where it was, notice that intent changed, recover the environment — and put it in infrastructure the engineering team can debug.
This is the same shape as the context-engine substrate and the prompt harness. Different substrates, same underlying engineering bet: in the medium term, the most reliable way to make agents better is to give them less to remember and more to look up.
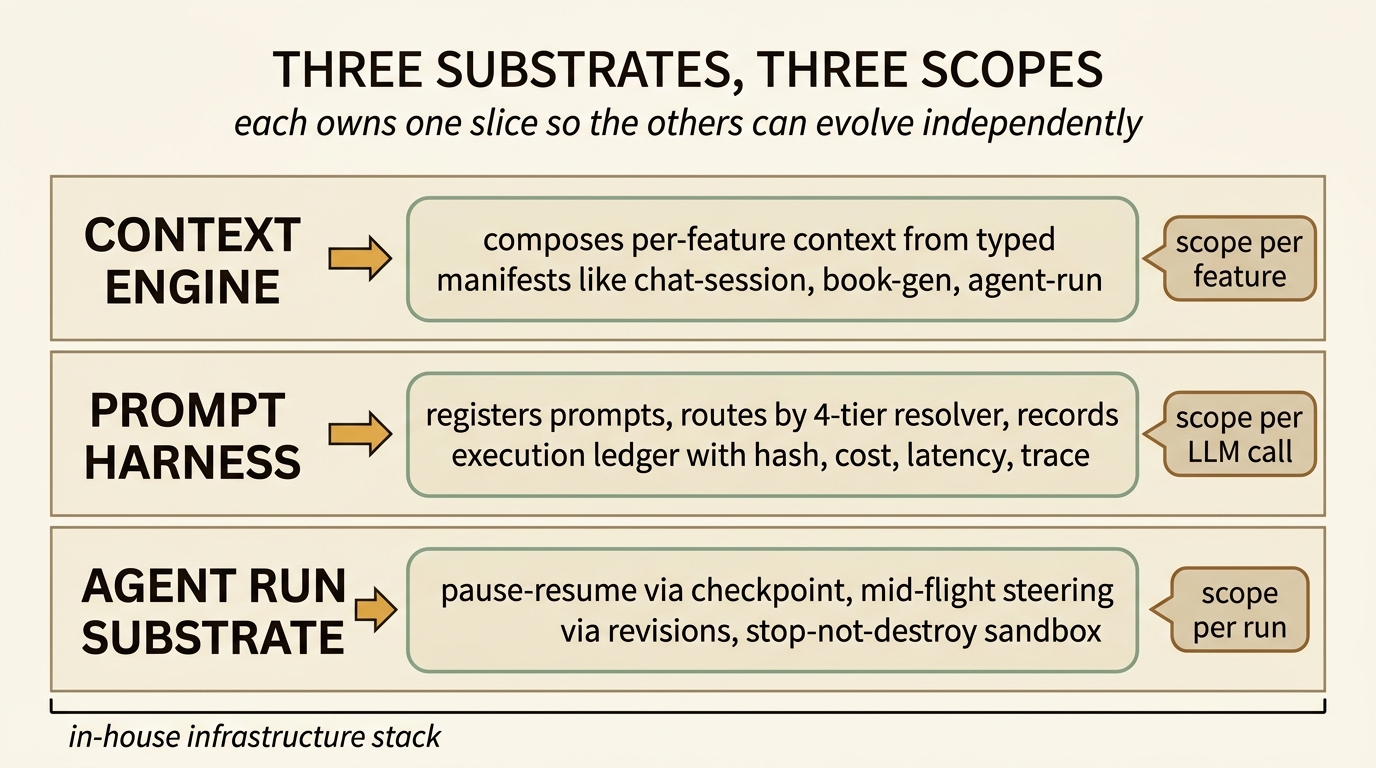
The narrower thing the agent-run substrate added is what Revisable by Design formalized as the stream paradigm: execution and intervention are concurrent processes sharing a channel, and that channel is a first-class infrastructure object — a table, not a thread. Once you accept that, the engineering rewrites itself. The executor is a loop with a polling step. The sandbox is a long-lived resource with stop-and-restart semantics. The user is a co-actor on the same channel, not a customer waiting at the end of a transaction.
If your agent runs are short and your users have not yet been bitten by mid-run regret, the transaction model is probably fine. If your users have started saying “I wish I could have told it earlier that…” — that is the signal. The shape we shipped is one of several possible answers; the 2026 literature now provides the vocabulary for picking between them. The wrong answer is to keep treating the agent run as a function call and hope nobody notices the mismatch.
Comments
Sign in with GitHub to leave a comment. Threads live on SourceShift/blog-comments — moderated.