How we built our user-profile system — the canonical six-layer pattern behind every personalized LLM call
Every LLM call our product makes — chat, explain, annotate, summarize, mind-map, retrieval-augmented answers, every surface — silently injects the same natural-language paragraph into the prompt: a short, dense description of who is on the other end. Register. Density. Depth. Tone. Mathematical comfort. Cultural register. How much they want explained versus assumed.
We call that paragraph the personality summary. The user never reads it directly — they see its effect, in the way the assistant talks to them. But it is the single most consequential string in the system, because it determines the voice of every response on every surface.
This post is about how we build it, how we keep it up to date, and how we inject it into the prompt harness without coupling.
The four names that all matter
The system has four names, and they describe four different layers of the same thing.
- Profile Maker is the page the user sees. They call it “the reading brain.” It is where they read the paragraph the AI uses, edit it directly if they want, regenerate it on demand, and adjust the underlying preferences via segmented controls.
- Personality summary is the natural-language paragraph itself — the artifact the AI consumes. It is bounded in length, written in second person, and rewritten from scratch whenever the underlying preferences change.
- Personality wiring is the plumbing — the contract that says every writer in the system that changes a user’s preferences must re-emit the canonical paragraph in the same transaction. It is what keeps the user’s view and the AI’s view in sync.
- User profile is the structured store underneath — a small set of typed atoms (tone, length, density, math comfort, domain, level, language) plus an evolving free-text “about me.” The paragraph is the verbalization of this store, not a parallel artifact.
The reason all four names matter is that each one is a place a bug can hide. When someone says “the personality is broken,” they could mean the UI is stale, the paragraph is wrong, a writer skipped the mirror, or the structured store has drifted from the user’s actual preferences. Naming the layers separately is what lets a question land on the right one.
The six-layer architecture
The system has six layers. Three of them are observation and inference: they listen to what the user does and turn it into a stable signal. Three of them are emission and injection: they turn that signal into a paragraph the model reads, with provenance respected at every step.
flowchart TD
SIGNALS([User Signals<br/><i>thumbs · dim nudges · about-me edits<br/>every interaction is a preference vote</i>])
SIGNALS --> L3
L3[<b>Preference Aggregator</b><br/><i>smooths noisy signals into a stable<br/>estimate of what the user actually wants</i>]
L3 --> L4
L4[<b>Drift Detector</b><br/><i>watches the gap between recent and long-term<br/>behavior · flags when the gap grows enough to matter</i>]
L4 --> L5
L5[<b>Profile Verbalizer</b><br/><i>turns the structured preferences into a<br/>natural-language paragraph at write-time</i>]
L5 --> L2
L2[<b>Provenance Guard</b><br/><i>tags every paragraph with its origin ·<br/>pinned user edits are never overwritten</i>]
L2 --> L1
L1[<b>Prompt Preamble</b><br/><i>reads the one canonical paragraph and<br/>prepends it on every LLM call</i>]
L1 --> HARNESS([Every AI Surface<br/><i>chat · explain · summarize · annotate ·<br/>RAG · mind-map · twenty-seven in all</i>])
HARNESS --> L6
L6[<b>Refinement Loop</b><br/><i>samples recent AI responses against user thumbs ·<br/>proposes one-sentence amendments when they diverge</i>]
L6 -.observed behavior.-> SIGNALS
classDef inference fill:#7a5a1f,stroke:#fff,stroke-width:2px,color:#fff
classDef emission fill:#1f5e3a,stroke:#fff,stroke-width:2px,color:#fff
classDef reader fill:#1f3a7a,stroke:#fff,stroke-width:2px,color:#fff
classDef io fill:#3a1f6e,stroke:#fff,stroke-width:2px,color:#fff
class L3,L4,L6 inference
class L5 emission
class L1,L2 reader
class SIGNALS,HARNESS ioThe flow is linear in one direction, with the refinement loop folding back into signals as a meta-observer. I walk the layers below in flow order — following the arrows above — not by number. The number is each layer’s depth in the stack, with Layer 1 sitting closest to the model; the signal enters from the outer layers and works inward.
Layer 3 — Preference Aggregator (flow step 1 of 6)
In our system, every meaningful user action becomes a preference observation. Thumbs on an AI-generated annotation. A nudge of one of the seven segmented controls in the Profile Maker (tone, length, density, math comfort, domain, level, language). An edit to the free-text about-me box. A skip on a suggested rewrite. A thumb on the live-preview panel. Each action is timestamped, tagged with the dimension it speaks to, normalised to a value (or a category index for categorical dims like language), and dropped into a rolling per-user signal log.
Two estimators run continuously over that log, per dimension. The short-window mean holds the last twenty signals — that is the reactive view: how this user has been behaving recently. The exponential moving average, with decay , integrates older but consistent evidence — that is the stable view: who this user has been over the long run. Both views are cheap to maintain; updating them on each new signal is a constant-time write.
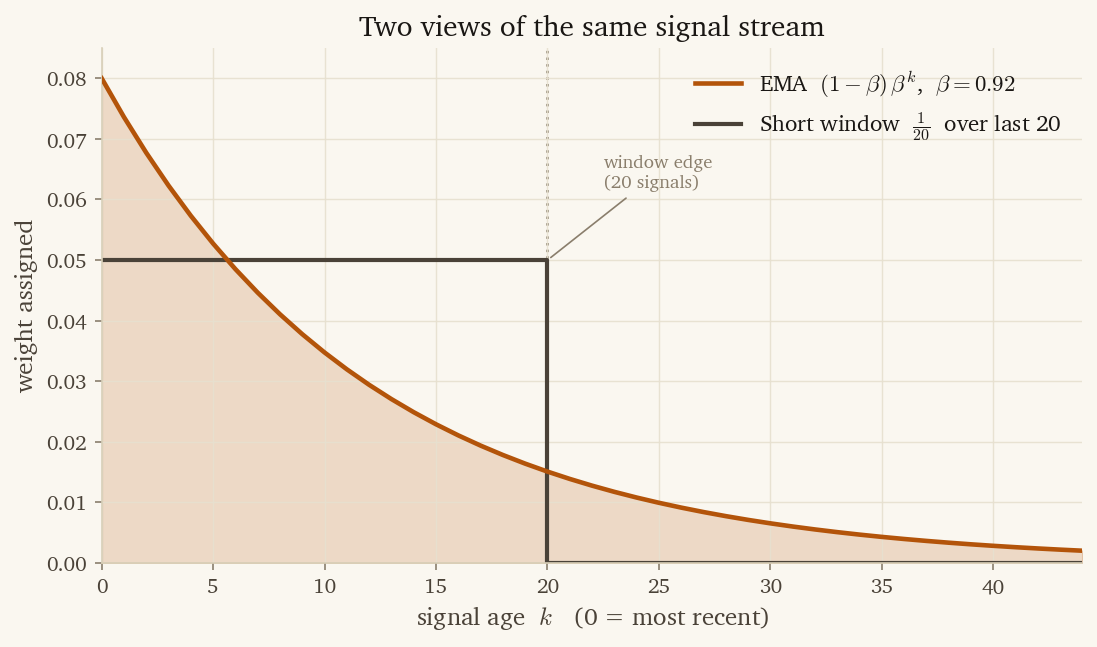
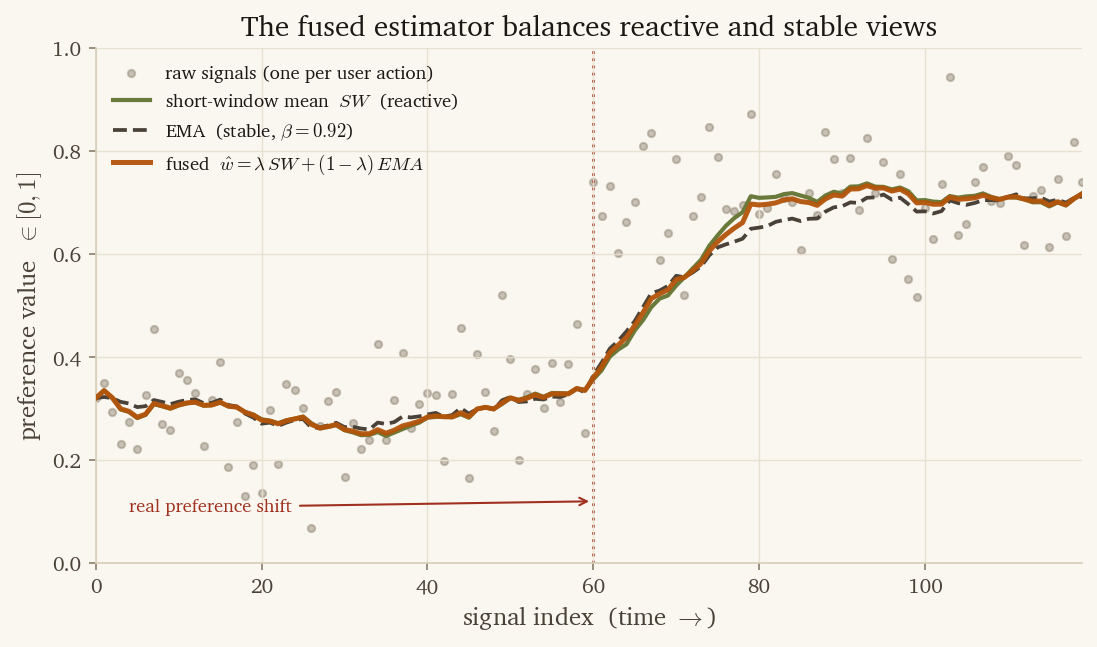
Neither view is right on its own. A single outlier session pulls the short-window mean toward noise. A real preference shift can take weeks to move the EMA. The dual-statistic estimator combines them into a single fused value:
where is data-dependent — it weights the short window more heavily when its variance is low (the user has been behaving consistently for the last twenty signals) and falls back to the EMA when the short window is noisy. That weighting isn’t a knob we tuned by hand. Trusting whichever view is currently steadier is just inverse-variance weighting — the textbook way to average two measurements of different reliability — so the formula falls out of the math instead of out of trial and error. We compute it on demand per dimension; reading all seven dimensions for one user takes a few milliseconds.
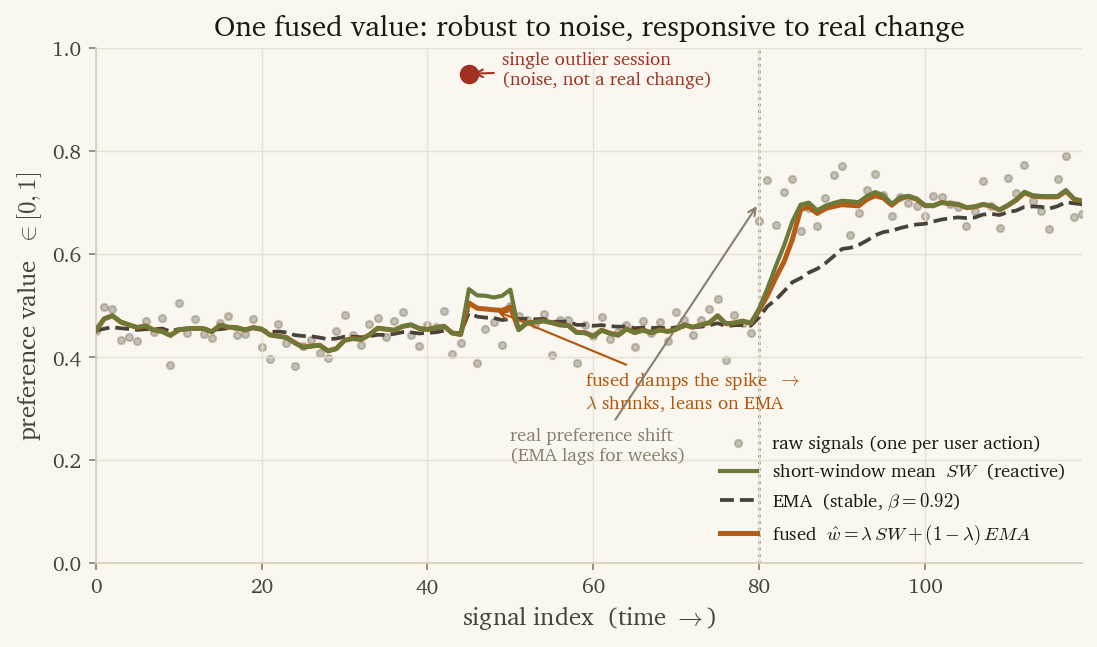
Layer 4 — Drift Detector (flow step 2 of 6)
The fused estimator is one value. The interesting question is when has it moved enough to matter?
A background drift detector runs every fifteen minutes. For each user, for each of the seven dimensions, it computes the gap between the short-window mean and the EMA, scaled by the square root of their joint variance:
The threshold is empirical — below it, the system is over-eager and re-evolves on noise; above , real drift goes undetected for weeks. We landed on after watching the false-positive rate on our own usage for a few hundred sessions.
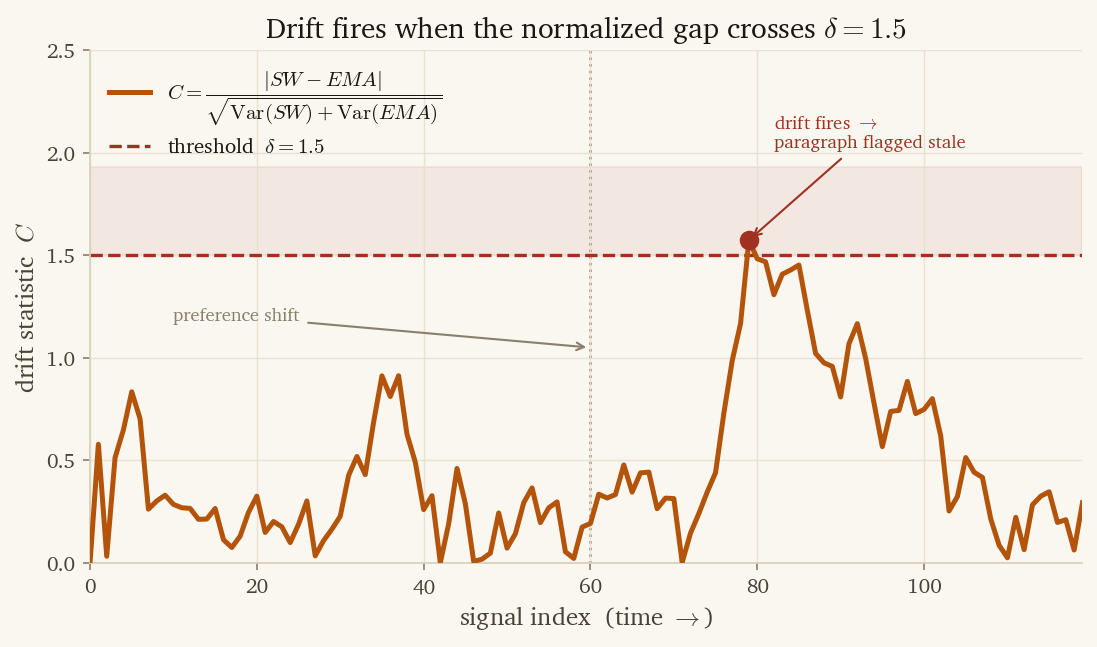
The detector’s output is binary per dimension: drift or no drift. When any dimension crosses the threshold, the user’s personality paragraph is flagged stale. The next step depends on provenance — that is Layer 2’s job. The detector itself never writes to the paragraph; it only flags. This separation is what lets the system observe drift on a pinned summary without violating the pin.
Layer 5 — Profile Verbalizer (flow step 3 of 6)
This is the layer that surprised us most when we read the papers.
The naive design generates the personality paragraph at prompt-build time, from the structured atoms, on every LLM call. That keeps the atoms canonical and the paragraph derived. It also burns a small LLM call on every chat turn, every annotation, every summarization — a cost that scales with traffic and a latency that adds tens of milliseconds to every request.
The literature converges on the opposite shape, and we follow it. Whenever the atoms change — at the end of the onboarding wizard, on every re-evolution triggered by drift, on every direct edit the user submits from the Profile Maker — a single fast-model call regenerates the paragraph end-to-end. The call takes under 800 ms in our pipeline and produces a bounded-length paragraph (under 300 words, second-person, written at a reading level that matches the user’s own density preference — low-density users get plainer language, expert-tier users get denser prose).
The atoms remain as the structured store. The paragraph becomes the canonical artifact every downstream surface reads. The cost of producing it happens once per change, not once per call. That difference is what makes Layer 1 fast and deterministic — twenty-seven LLM surfaces share one read with no LLM call between the store and the harness.
Layer 2 — Provenance Guard (flow step 4 of 6)
Not all paragraphs are equal. Every personality paragraph in the system carries a provenance tag, and the system reads that tag before acting on drift.
| Provenance | Source | Treatment |
|---|---|---|
| User-authored | The user typed it themselves in the Profile Maker editor and clicked Save | Pinned. Background workers respect the pin — they observe drift but never auto-overwrite. |
| Evolved | The system regenerated it after a divergence event from observed behavior | Live. Subject to future re-evolution when drift detected. |
| Onboarding | The first-run wizard wrote it after the seven-question quiz | Live. Replaced by an evolved paragraph once roughly thirty thumbs + ten dim adjustments have accumulated. |
| Empty | The user has never onboarded | The harness injects no preamble at all. |
The ladder is what lets automation and explicit user control coexist. When the user clicks Save on their edited paragraph, the system flips the provenance to user-authored. From that point on, every background process — the drift detector, the re-evolution worker, the refinement loop — checks the pin before acting. A pinned paragraph is observed but never written through. The user can clear the pin via a button in the Profile Maker, which re-enables full automation.
The literature is clear on this: manually-created profiles drift from observed behavior over time, but silently replacing them violates the user’s explicit override. The fix is not to disable automation when the user pins; it is to surface proposed amendments as suggestions instead of writing them through. That is what Layer 6 does on top of this ladder.
Layer 1 — Prompt Preamble (flow step 5 of 6)
The prompt harness reads exactly one place. Every LLM call on every surface — twenty-seven of them in our current product: chat over arXiv papers, AI annotations on highlights, paragraph summaries, mind-map generation, RAG over a user’s library, structured book-chapter generation, translation-style preservation, language switching, suggested-rewrite previews, and the rest — pulls the personality paragraph from the same canonical store and auto-prepends it as preamble before the surface-specific prompt body is appended.
No surface has its own override path. No fast cache lives between the store and the harness. No per-call rewriting fires. The discipline is enforced via a single grep in our codebase — the read function appears once, and any pull request that introduces a second one fails review.
This is the load-bearing invariant of the whole design. Adding a second read path is how you get drift between what the user sees on the Profile Maker and what the AI receives in the prompt. The literature ablation on the preamble is striking: removing it from the prompt drops perceived personalization by three to five percentage points across multiple evaluation surfaces. The preamble is not a nice-to-have; it is the personalization mechanism.
Layer 6 — Refinement Loop (flow step 6 of 6)
The system has one more job: keep itself honest.
Every twenty AI-generated responses on a given user account, a background job samples five of them at random along with the thumbs the user attached. The sample is small enough to keep the cost negligible (one fast-model call per refinement check) and large enough that real divergence is detectable.
The job runs a cognitive divergence check: does the current personality paragraph predict the kind of response the user is actually approving? If the paragraph says “prefers concise, no-jargon explanations” but the user is consistently thumbing-up dense, math-rich responses, that is divergence — the paragraph and the behavior have drifted apart. When divergence shows up, the job emits a one-sentence amendment proposal.
What happens to the amendment depends on the provenance tag from Layer 2:
- If the paragraph is evolved, the amendment is folded into the next re-evolution and the paragraph updates seamlessly.
- If the paragraph is user-authored, the amendment never writes through. Instead it surfaces in the Profile Maker as a refinement banner: “I notice your recent thumbs diverge from your saved description. Here is a suggested one-sentence amendment — accept, edit, or dismiss.” The user is the only one who can promote it.
- If the paragraph is onboarding-stage and the signal threshold for evolution is met, the amendment triggers the first evolution rather than waiting for the next drift event.
This is what closes the loop from emission back to observation. Without it, the system can drift indefinitely while believing its profile is current. With it, the paragraph keeps its calibration against the user’s actual responses, not the user’s recollection of their preferences from a year ago.
Where the architecture comes from
The six layers are not original. Four papers in late 2025 / early 2026 converged on this exact shape, each owning one to two layers of the architecture.
- Persistent Memory and User Profiles for LLM-based Agents — Westhäußer, Minker, Zepf (arxiv 2510.07925). Defines the user profile as a structured JSON store verbalized into natural language at write-time. Ablates the profile component and shows it carries three to five percentage points of perceived personalization on its own. Owns layers 1 and 5.
- User Profile Construction and Updating — Prottasha (arxiv 2502.10660). Formalizes the update operation:
(old_profile, new_signal) → new_profile, with the update emitting a canonical re-verbalized form, not a substructure mutation. Owns the discipline behind layer 5. - PAMU — Preference-Aware Memory Update — Sun (arxiv 2510.09720). Introduces the dual-statistic estimator (short window + EMA) with the confidence-weighted fusion and the divergence detector. Reports style-consistency lift from 37/35% to 92/94% (GPT-judge / human-judge). Owns layers 3 and 4.
- DPRF — Dynamic Persona Refinement — Yao (arxiv 2510.14205). Defines the refinement loop, including the cognitive-divergence detection criterion and the never-overwrite-a-pinned-profile rule. Five-LLM × four-scenario evaluation across creative writing, summarization, dialogue, and recommendation. Owns layers 2 and 6.
The convergence across four independent groups on the same six-layer shape is the strongest signal we have that this is the natural decomposition of the problem. None of them set out to write the same paper; they wrote the same paper anyway because the failure modes they were addressing all decompose into the same layers.
The discipline that holds it together
Architecture is necessary but not sufficient. The six layers are an organizational decomposition; the rules below are what keeps the system coherent in practice.
- Single canonical read. The harness reads one place. Caches, per-surface variants, and override paths are forbidden — they are the mechanism by which the user’s view drifts from the AI’s view.
- All writers mirror. Anything that changes the user’s preferences must emit the new canonical paragraph in the same transaction. There is no “I will update the atoms now and the paragraph later” path.
- Pin semantics are sacred. A user-authored paragraph is never silently overwritten by automation. The refinement loop proposes; the user accepts or rejects.
- Verbalize at write-time. The expensive work (turning atoms into a paragraph) happens when atoms change, not when prompts are built. The harness read is fast and deterministic.
- Zero-fallback on empty. If the user has not onboarded, the harness injects no preamble. The system never fabricates a default personality from thin air.
These five rules are the architecture in operational form. They are the parts of the design that, when violated, produce the specific bugs the literature is built to prevent.
Why this matters past the chat surface
The personality summary is the most visible application of this pattern, but the pattern itself is general. Any LLM-driven system that needs to behave consistently across many surfaces — agent harnesses, customer-support copilots, multi-document research assistants, code editors with memory — runs into the same six layers.
The signal layer changes (clicks instead of thumbs, accepted suggestions instead of nudge changes). The verbalization layer changes (a system prompt fragment instead of a personality paragraph). The harness changes. But the architecture is the same: aggregate noisy observations, detect divergence, verbalize on write, respect provenance, read from one place, refine against behavior.
The systems that fail tend to fail at one specific layer. They aggregate but never verbalize, so the prompt gets a JSON blob that the model misreads. They verbalize but never detect divergence, so the prompt is stable for months while the user has moved on. They write to one column and read from another, so the user’s explicit edits never reach the model. The architecture above is not a guarantee of correctness — it is a list of the failure modes that have been documented in print and the layer at which each one belongs.
We treat that list as the bar, and the six layers as the answer.
Comments
Sign in with GitHub to leave a comment. Threads live on SourceShift/blog-comments — moderated.